HD9001: 各浏览器对 URI 中非 ASCII 字符的处理有差异
标准参考
URI 的组成如下所示:
foo://example.com:8042/over/there?name=ferret#nose \_/ \______________/\_________/ \_________/ \__/ | |
| | | scheme authority path query fragment | _____________________|__ / \ / \
urn:example:animal:ferret:nose
根据 HTML 4.01 规范中的描述,URI 中不应该包含非 ASCII 字符。如以下 href 属性的值是不合法的:
<A href="http://foo.org/Håkon">...</A>
规范中建议,用户端在这种情况下应采取以下方式处理非 ASCII 字符:
- 将每个字符转换为 UTF-8 编码的相同字符,每个字符将有一或多个字节。
- 用 URI 编码机制对这些字节进行编码。如:每个字节转换为 %HH,其中的 HH 为这些字节的值的十六进制表示。这种方式称为“百分号编码”。
关于 URI 类型及 URI 属性值中的非 ASCII 字符(Non-ASCII characters in URI attribute values)的详细信息,请参考 HTML4.01 规范 6.4 URIs 及 附录B.2.1 中的内容。
关于“百分号编码”的详细信息,请参考 RFC-3986 2.1. Percent-Encoding 中的内容。
关于 URI 组成的更多信息,请参考 RFC-3986 3. Syntax Components 中的内容。
问题描述
对于 URI 中非 ASCII 字符,并非所有浏览器都是按照 HTML 4.01 规范中的建议实现的,而且不同浏览器在处理不同形式的 URI 时,表现也有差异。
造成的影响
这个问题将导致在服务端或客户端通过代码获取 URI 中的非 ASCII 字符信息时无法分辨编码信息,并产生乱码。
受影响的浏览器
| 所有浏览器 |
|---|
问题分析
下面测试各种情况下各浏览器对于 URI 中非 ASCII 字符的编码方式。
在应用中经常使用的编码是 GB2312 和 UTF-8,一个汉字在 GB2312 编码下占 2 个字节,在 UTF-8 编码下占 3 个字节,因此通过对比这两种编码更容易看出区别。下面的例子中将分别使用这两种编码测试。
- 测试使用的非 ASCII 字符均为中文字符“汉”,“汉”在 GB2312 编码中的字节码为“BA BA”,在 UTF-8 编码中的字节码为“E6 B1 89”。
- 测试结果的截图中,所有字符均为 ASCII 编码,GB2312 编码的“汉”以 ASCII 编码显示时,为“ºº”,UTF-8 编码的“汉”以 ASCII 编码显示时,为“æ±ᄆ”(第三个字节在 ASCII 字符集中无对应字符,因此显示为“ᄆ”)。
-
测试的访问地址均为:
http://local.test/BrowserName/汉?汉=汉1
为了便于区分各浏览器的表现,BrowserName 将在测试中替换为各浏览器名。 -
另外,当声明一段测试代码是 GB2312 编码时,其含义为该 HTML 文件的编码为 GB2312,并且在该文件中声明了:
<meta http-equiv="Content-Type" content="text/html; charset=gb2312"/>
同样,当声明一段测试代码是 UTF-8 编码时,其含义为该 HTML 文件的编码为 UTF-8,并且在该文件中声明了:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
注:
1. 此处的“汉”字,在不同测试中,实际的编码也不相同。
1. 在浏览器的地址栏直接输入包含非 ASCII 字符的 URI 时
在各浏览器的地址栏中,直接输入“http://local.test/BrowserName/汉?汉=汉”,结果如下:1
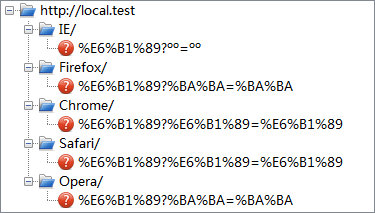
可见,对于 URI 中的非 ASCII 字符:
- 在 path 部分,所有浏览器都使用了 UTF-8 并做了百分比编码。
- 在 query 部分,IE 使用了 GB2312,未做百分比编码;Firefox 和 Opera 使用了 GB2312,做了百分比编码;Chrome 和 Safari 则仍使用 UTF-8 并做了百分比编码。
注:
1. 因各浏览器的地址栏使用的编码未能确定,本测试仅强调 URI 中 非 ASCII 字符最终使用的字符集。
2. 点击链接跳转或使用脚本跳转到包含非 ASCII 字符的 URI 时
在不同的编码下,测试以下两段代码:
<button
onclick="location.href='http://local.test/BrowserName/汉?汉=汉';">go</button>
<a href="http://local.test/BrowserName/汉?汉=汉">go</a>
点击按钮或链接后,各浏览器实际发送的 URI 如下:
| GB2312 | 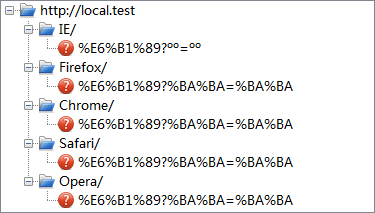 |
|---|---|
| UTF-8 | 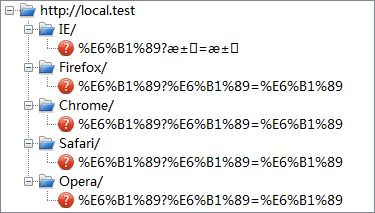 |
可见,对于 URI 中的非 ASCII 字符:
- 在 path 部分,所有浏览器都转换为 UTF-8,做了百分比编码。
- 在 query 部分,IE 使用当前编码,未做百分比编码;其他浏览器则使用当前编码做百分比编码。
3. 使用 Ajax 请求包含非 ASCII 字符的 URI 时(get 方法)
在不同的编码下,测试以下代码:
<script> function go(){ var xhr=window.XMLHttpRequest?new XMLHttpRequest():new
ActiveXObject("Microsoft.XMLHTTP");1
xhr.open("get","http://local.test/BrowserName/汉?汉=汉",true);2 xhr.send(null); }
</script> <button onclick="go();">go</button>
点击按钮后,各浏览器实际发送的 URI 如下:
| GB2312 | 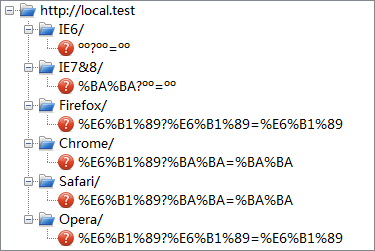 |
|---|---|
| UTF-8 | 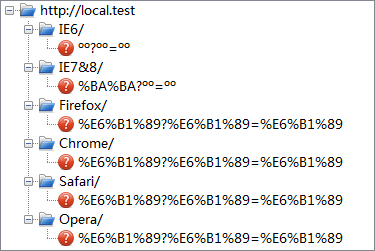 |
可见:
- IE 无视页面编码设置,将任意编码的字符转换为 GB2312 发送请求,并且对于 URI 中的非 ASCII 字符处理如下:
- 在 path 部分,IE6 并未处理;IE7 IE8 则做百分比编码。
- 在 query 部分,IE 并未对其处理。
- 其他浏览器对于 URI 中的非 ASCII 字符处理如下:
- 在 path 部分,均转换为 UTF-8 并做百分比编码。
- 在 query 部分,Firefox Opera 转换为 UTF-8 并做百分比编码,Chrome Safari 则使用当前编码做百分比编码。
注:
1. 这段代码仅为测试编码用,因此并未设置 Ajax 请求的回调函数及后续处理,并且对于 IE7 IE8,使用 XMLHttpRequest 创建的 xhr 对象和使用 ActiveXObject 创建的 xhr
对象的测试结果没有区别。
2. 假设这段代码所在域为 local.test,即不会有跨域的问题。
4. 差异总结
根据以上的测试,总结各浏览器对 URI 中非 ASCII 字符的处理的差异如下:
地址栏直接输入:
| 浏览器 | path 部分 | query 部分 | ||
|---|---|---|---|---|
| 使用 UTF-8 | 百分比编码 | 使用 UTF-8 | 百分比编码 | |
| IE | 是 | 是 | 否 | 否 |
| Firefox Opera | 是 | 是 | 否 | 是 |
| Chrome Safari | 是 | 是 | 是 | 是 |
点击链接跳转或使用脚本跳转:
| 浏览器 | path 部分 | query 部分 | ||
|---|---|---|---|---|
| 转换为 UTF-8 | 百分比编码 | 转换为 UTF-8 | 百分比编码 | |
| IE | 是 | 是 | 否使用页面编码 | 否 |
| Firefox Chrome Safari Opera | 是 | 是 | 否使用页面编码 | 是 |
使用 Ajax 的 get 方法请求:
| 浏览器 | path 部分 | query 部分 | ||
|---|---|---|---|---|
| 使用 UTF-8 | 百分比编码 | 使用 UTF-8 | 百分比编码 | |
| IE6 | 否无视页面编码使用 GB2312 | 否 | 否无视页面编码使用 GB2312 | 否 |
| IE7 IE8 | 否无视页面编码使用 GB2312 | 是 | 否无视页面编码使用 GB2312 | 否 |
| Firefox Opera | 是 | 是 | 是 | 是 |
| Chrome Safari | 是 | 是 | 否使用页面编码 | 是 |
解决方案
当 URI 中含有非 ASCII 字符时,不要依赖浏览器对 URI 的编码方式,以避免产生差异。建议:
- 在使用此 URI 之前,先对其进行处理,如使用 JS 的 encodeURI 或 encodeURIComponent 方法(JS 的这两个方法会将字符串转换为 UTF-8 并做百分比编码)。
- 在使用 XHR 对象发送 Ajax 请求时,如果仅在 query 部分含有非 ASCII 字符,请使用 post 方法发送,并在 send 之前使用
xhrObject.setRequestHeader("Content-Type","application/x-www-form-urlencoded")。或者仍使用 get 方法,但在发送前使用 encodeURI 或 encodeURIComponent 方法编码。 - 经过上述处理,在此 URI 的接收端使用 UTF-8 编码来解码,如:
- 客户端
JS:
var queryString = decodeURI(uriString or queryString);
- 服务端 JAVA:
request.setCharacterEncoding("UTF-8"); String queryString = request.getParameter(queryName);
- 客户端
JS:
参见
知识库
相关问题
测试环境
| 操作系统版本: | Windows 7 Ultimate build 7600 |
|---|---|
| 浏览器版本: |
IE6
IE7 IE8 Firefox 3.6.8 Chrome 6.0.495.0 dev Safari 5.0(7533.16) Opera 10.60 |
| 测试页面: | 无 |
| 本文更新时间: | 2010-08-20 |
关键字
URI URL ASCII 地址栏 中文 乱码 escape unescape encodeURI decodeURI

